理解欠拟合与过拟合
2022-01-08 09:30:23 机器学习 编辑:黎为乐
拟合形象的说,拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。而模型的训练就是通过反向传播不断地调整参数,然后拟合出一条完美的线(一维意义上的)。
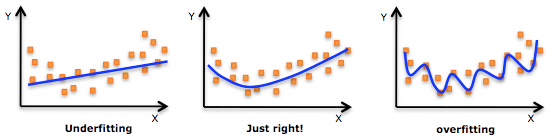
欠拟合指的就是模型拟合效果差,其误差值与实际值一直很大,没有趋于下降的形式。这种情况一般在刚开始训练就可以观察到,其原因是因为模型太过简单,权值太少,这样会导致模型学不到数据的规律。
eg.给了一个权重w,偏置b来拟合sinx,你无法找到一个完美的线去拟合这条直线,实际上,权重w给再多也不能太好的拟合,这是因为权重w不管怎么增加,这都是只是线性可分。而sinx是一个非线性的函数,这边我们假设引入了一个激活函数来解决这种线性不可分的问题,参数量不变(一个权重w,偏置b),这样能完美拟合sinx吗,加入了激活函数过后,拟合效果会比没有使用激活函数效果要好,但依然不能较好的拟合sinx。这时候我们不断增加权值w的数量,增加模型的复杂度,让更多的参数去描述这条曲线,这样才能更好的拟合sinx这条曲线。
为什么说一个权值无法去描述sinx,因为这个太简单了,y=wx+b,这就是在xOy上的一条直线,而sinx泰勒展开后是个很复杂的函数表达式:sinx=x-(x^3/3!)+...+{(-1)^k}{x^(2k+1)/(2k+1)!}+{x^(2k+3)/(2k+3)!}sinx(θx+(2k+3/2)π。这个表达式一看很吓人,或许有些看不懂,但这无伤大雅,这时候让你去用y=wx+b去拟合这条曲线,你有什么好的办法呢。显然的,你永远永远找不到一个合适的参数来描述它。这时候你只需要通过增加参数量来增加模型复杂度,就可以很好的拟合这条曲线了(使用激活函数)。
那欠拟合说完了,过拟合又是什么,过拟合通俗易懂的来说就是,训练的太好了,这有可能是权值太多,让模型达到了死记硬背的程度,导致模型在验证集上一塌糊涂(泛化能力差),我们的想法一定是想让模型能找到其事物背后的规律,权值太多,就会导致模型描述的过好。还有就是数据集太单一了,也就是数据多但学到的东西不是很多。再其次,数据集的噪音太大,也会导致过拟合问题。过拟合通常体现在训练集上的损失会不断下降,而放到验证集上就不仅不下降,还有上升的趋势,这种情况很多见,而且只能在训练后期才能体现出来。
那么怎么有效的避免过拟合呢,先人已经找到了许多技巧,这边copy一下。
1.获取和使用更多的数据(数据集增强)——解决过拟合的根本性方法2. 采用合适的模型(控制模型的复杂度)3. 降低特征的数量 4. L1 / L2 正则化5. Dropout6. Early stopping(提前终止)
这些都是一些非常好的解决过拟合问题的方法,当然如果你不理解这些是什么,再后续我会逐一发表文章来解释这些。 如果你还是不能明白这些,那么我有这么一张图,会让你眼睛一亮的。